發布日期:2022-10-18 點擊率:92
AI 芯片的誕生
講到半導體,不得不從摩爾定律說起。從Intel創始人戈登·摩爾提出摩爾定律到現在已經53年了。過去的53年中,半導體行業一直受著摩爾定律的指導。芯片越做越小,單位面積的晶體管越來越多,功耗越來越低,價格越來越便宜,也使得這個行業過去五十多年來一直保持不錯的增長趨勢。網上對AI芯片的剖析實在太少,這里對一些論文和大佬的研究做一個總結,希望對讀者有所幫助。
但是半導體行業風險高、投資大、回報相對來說又比較低的特點使風投對半導體行業的投資在過去十來年一直不溫不火,甚至是持續下降的趨勢。尤其是現在到了后智能手機時代或者說后摩爾時代,半導體急需新的技術或者新的應用場景來推動其發展。那么新的技術和新的應用場景是什么呢?
其實戈登·摩爾在五十三年前已經說了“集成電路會帶來家用電腦或者至少是和中央電腦所連接的終端設備、自動駕駛、個人便攜通訊設備等”。沒錯,智能手機后下一個推動集成電路發展的新的應用場景是自動駕駛和物聯網。
除了新的應用場景外,新的技術革命也必須為半導體發展提供動力,新的技術革命是什么呢,沒錯,就是人工智能。人工智能的出現可以說讓所有行業眼前一亮,剛剛提到的無人駕駛,物聯網等等背后也都是因為 AI 的出現才帶來這樣巨大的,有前景的應用。也就是說 AI 技術的變革才是集成電路新應用場景落地的本質所在。
我們知道上游芯片公司的發展一向是穩中緩進,為什么說 AI 的發展會使芯片再次火熱起來?
我們可以把馮諾依曼架構的五大組成部分分為三類,輸入輸出歸類于交互,控制和邏輯歸類于計算,存儲單獨列為一類,也就是交互、計算和存儲三部分。而傳統的計算力無法滿足深度學習大量數據的運算,深度學習對這三方面都提出了非常多的創新要求,故新的計算架構需要為 AI 算法提供支撐。
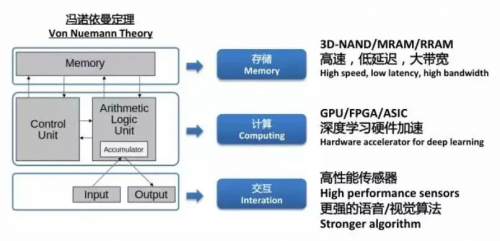
下面我們從以上三點闡述下目前比較主流的深度學習在芯片層面實現加速的方法。
AI 芯片的加速原理
乘加運算硬件加速,脈沖陣列
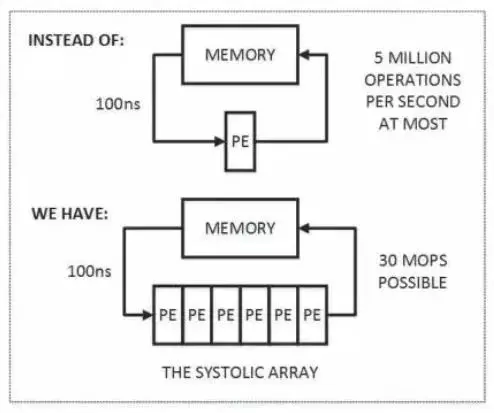
脈動陣列并不是一個新鮮的詞匯,在計算機體系架構里面已經存在很長時間。大家可以回憶下馮諾依曼架構,很多時候數據一定是存儲在memory里面的,當要運算的時候需要從memory里面傳輸到Buffer或者Cache里面去。當我們使用computing的功能來運算的時候,往往computing消耗的時間并不是瓶頸,更多的瓶頸在于memory的存和取。所以脈動陣列的邏輯也很簡單,既然memory讀取一次需要消耗更多的時間,脈動陣列盡力在一次memory讀取的過程中可以運行更多的計算,來平衡存儲和計算之間的時間消耗。
下面說下脈沖陣列的基本原理:
首先,圖中上半部分是傳統的計算系統的模型。一個處理單元(PE)從存儲器(memory)讀取數據,進行處理,然后再寫回到存儲器。這個系統的最大問題是:數據存取的速度往往大大低于數據處理的速度。因此,整個系統的處理能力(MOPS,每秒完成的操作)很大程度受限于訪存的能力。這個問題也是多年來計算機體系結構研究的重要課題之一,可以說是推動處理器和存儲器設計的一大動力。而脈動架構用了一個很簡單的方法:讓數據盡量在處理單元中多流動一會兒。
正如上圖的下半部分所描述的,第一個數據首先進入第一個PE,經過處理以后被傳遞到下一個PE,同時第二個數據進入第一個PE。以此類推,當第一個數據到達最后一個PE,它已經被處理了多次。所以,脈動架構實際上是多次重用了輸入數據。因此,它可以在消耗較小的memory帶寬的情況下實現較高的運算吞吐率。
上面這張圖非常直觀的從一維數據流展示了脈動陣列的簡單邏輯。當然,對于CNN等神經網絡來說,很多時候是二維的矩陣。所以,脈動陣列從一維到二維也能夠非常契合CNN的矩陣乘加的架構。
優化 Memory 讀取
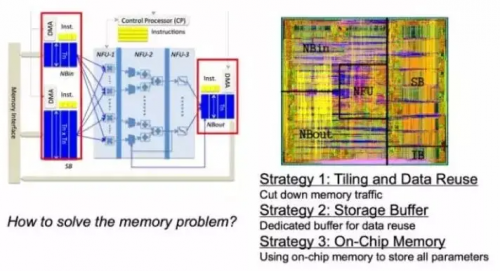
還可以從體系架構上對整個的Memory讀取來做進一步的優化。這里摘取的是寒武紀展示的一些科研成果。其實比較主流的方式就是盡量做Data Reuse,減少片上Memory和片外Memory的信息讀取次數,增加片上memory,因為片上數據讀取會更快一點,這種方式也能夠盡量降低Memory讀取所消耗的時間,從而達到運算的加速。
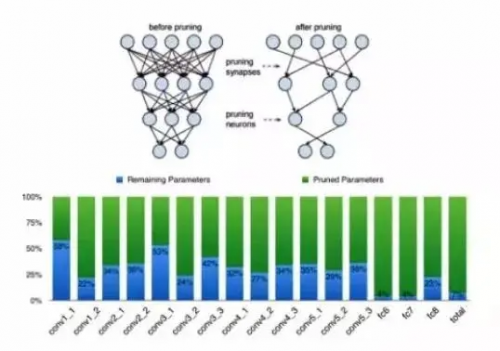
對于神經網絡來說,其實很多的連接并不是一定要存在的,也就是說我去掉一些連接,可能壓縮后的網絡精度相比壓縮之前并沒有太大的變化。基于這樣的理念,很多剪枝的方案也被提了出來,也確實從壓縮的角度帶來了很大效果提升。
需要特別提出的是,大家從圖中可以看到,深度學習神經網絡包括卷積層和全連接層兩大塊,剪枝對全連接層的壓縮效率是最大的。下面柱狀圖的藍色部分就是壓縮之后的系數占比,從中可以看到剪枝對全連接層的壓縮是最大的,而對卷積層的壓縮效果相比全連接層則差了很多。
所以這也是為什么,在語音的加速上很容易用到剪枝的一些方案,但是在機器視覺等需要大量卷積層的應用中剪枝效果并不理想。
權重系數壓縮

對于整個Deep Learning網絡來說,每個權重系數是不是一定要浮點的,定點是否就能滿足?定點是不是一定要32位的?很多人提出8位甚至1位的定點系數也能達到很不錯的效果,這樣的話從系數壓縮來看就會有非常大的效果。從下面三張人臉識別的紅點和綠點的對比,就可以看到其實8位定點系數在很多情況下已經非常適用了,和32位定點系數相比并沒有太大的變化。所以,從這個角度來說,權重系數的壓縮也會帶來網絡模型的壓縮,從而帶來計算的加速。
當然,一個不能回避的問題是計算和存儲之間的存儲墻到現在為止依然存在,仍然有大量的時間消耗在和存儲相關的操作上。
一個很簡單直觀的技術解決方式,就是堆疊更多更快速更高效的存儲,HBM孕育而生,也即在運算芯片的周圍堆疊出大量的3D Memory,通過通孔來連接,不需要與片外的接口進行交互,從而大大降低存儲墻的限制。
更有甚者提出說,存儲一定要和計算分離嗎,存儲和運算是不是可以融合在一起,PIM(Processing in Memory)的概念應運而生。

除了前面說到存儲內置,以及存儲與運算的融合,有沒有一個更快的接口能夠加速和片外Memory的交互也是一個很好的方向。其實上面這個概念是NVIDIA提出來的interface(接口),叫做NVLink。下面的表展示的是NVLink和PCIe Gen3的對比。大家平時看到跟存儲相關的的PCIe卡可能是PCIe Gen3 by 4,只有4個lanes和Memory對接,但是NVLink與有16個PCIe的lanes的PCIe Gen3對比,速度也有很大的提升,可以看到NVLink在速度層面是一個非常好的interface。
上面講了一些比較經典的加速方法。下面分享幾個已經存在的AI加速芯片的例子,相信這樣會更加直觀。
AI 芯片實例
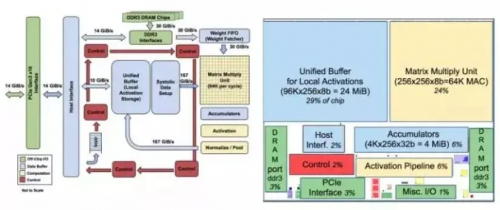
這是Google的TPU。從上邊的芯片框圖可以看到,有一個64K的乘加MAC陣列對乘加運算進行加速。從論文中可以看到里面已經用到了脈動陣列的架構方法來對運算進行加速,另外也有我們前面提到的大量的片上Memory 這樣的路徑。上面藍色框圖中大家可以看到有一個24MiB的片上Memory,而且有兩個高速DDR3接口能夠與片外的DDR做交互。
TPUv2
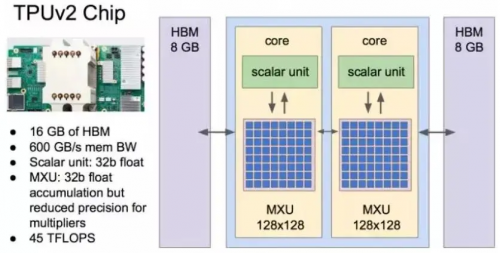
上圖展示的第二代TPU。從圖中可以很直觀的看到,它用到了我們前面所說到的HBM Memory。從其論文披露的信息也可以看到,二代TPU在第一代的基礎上增加了我們前面說到的剪枝,權重壓縮等方面做了很多嘗試,也是一個非常經典的云端AI加速芯片的例子。
接下來跟大家分享幾個終端做Inference的例子。
Rokid

這一個是Rokid和杭州國芯共同打造的一顆針對智能音箱的SoC,AI加速只是里面的一個功能。通過上面右邊的框圖可以看到里面集成了Cadence的DSP,還有自己設計的語音加速硬件IP——NPU。這款芯片還集成了一些實現智能音箱必要的interface,最值得一提的是在SiP層面封裝了Embedded DRAM,可以更好的在系統層面實現數據的交互,實現存儲和運算的加速,也實現了AI加速的功能。
HiSilicon Hi3559A

這是一款華為海思最新的IP Camera芯片——3559A,從集成度以及整個設計的均衡性來說,都令人眼前一亮。可以看下右上角幾個藍色的標準模塊,里面集成的是海思自主研發的做推理的IP——NNIE,同時還集成了Tensilica DSP,在靈活性和擴展度上做了一個非常好的補充。
下一篇: PLC、DCS、FCS三大控
上一篇: 射頻電路的電源設計要